本文档基于 RTX 4090 (24GB) 环境,记录 Ollama 的 GPU 加速部署流程。重点对比三款模型在实际安全扫描场景中的推理表现,通过实测数据确定主力模型规格,确保服务的稳定性与响应速度。
结论:
- 推荐:Qwen2.5-Coder 14B —— 漏洞检出率最高(10个),响应最快(15秒),分析准确,完全 GPU 加速
- 备选:DeepSeek-R1 14B —— 检出率较低(1个),速度较慢(76秒),但适合复杂攻击链分析等深度推理场景
- 不推荐:Qwen3:27B —— 显存不足导致 CPU 混合推理,性能抖动明显,响应延迟高
一、环境信息
| 项目 | 配置 |
|---|---|
| GPU | RTX 4090 24GB |
| 驱动 | 560.x |
| CUDA | 12.6 |
| 内存 | 32GB |
| 系统 | Ubuntu 22.04 |
| Ollama | 0.22+ |
二、安装 Ollama
1、下载并安装
wget https://ollama.com/download/ollama-linux-amd64.tar.zst
tar -xf ollama-linux-amd64.tar.zst -C /
ollama -v2、配置 systemd 服务
vi /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
ExecStart=/usr/bin/ollama serve
Restart=always
RestartSec=3
User=ollama
Group=ollama
[Install]
WantedBy=multi-user.target3、创建用户并授权 GPU
useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
usermod -a -G ollama $(whoami)
usermod -a -G video ollama
usermod -a -G render ollama4、启动服务
systemctl daemon-reexec
systemctl daemon-reload
systemctl enable ollama
systemctl start ollama
systemctl status ollama三、安装模型
1、Qwen2.5-Coder 14B(推荐)
ollama pull qwen2.5-coder:14b模型大小:下载约 9GB,运行占用显存约 15~17GB
2、DeepSeek-R1 14B(备选)
ollama pull deepseek-r1:14b模型大小:下载约 9GB,运行占用显存约 15~17GB
3、Qwen3:27B(测试验证,不推荐)
ollama pull qwen3:27b模型大小:下载约 17GB,运行占用显存约 22~24GB(接近上限)
四、运行测试
启动模型
ollama run qwen2.5-coder:14b
ollama run deepseek-r1:14b
ollama run qwen3:27b
ollama ps #确认 GPU 是否生效五、GPU 状态监控
1、实时监控命令
watch -n 1 nvidia-smi2、各模型 GPU 状态对比
| 模型 | 显存占用 | GPU 利用率 | 推理模式 |
|---|---|---|---|
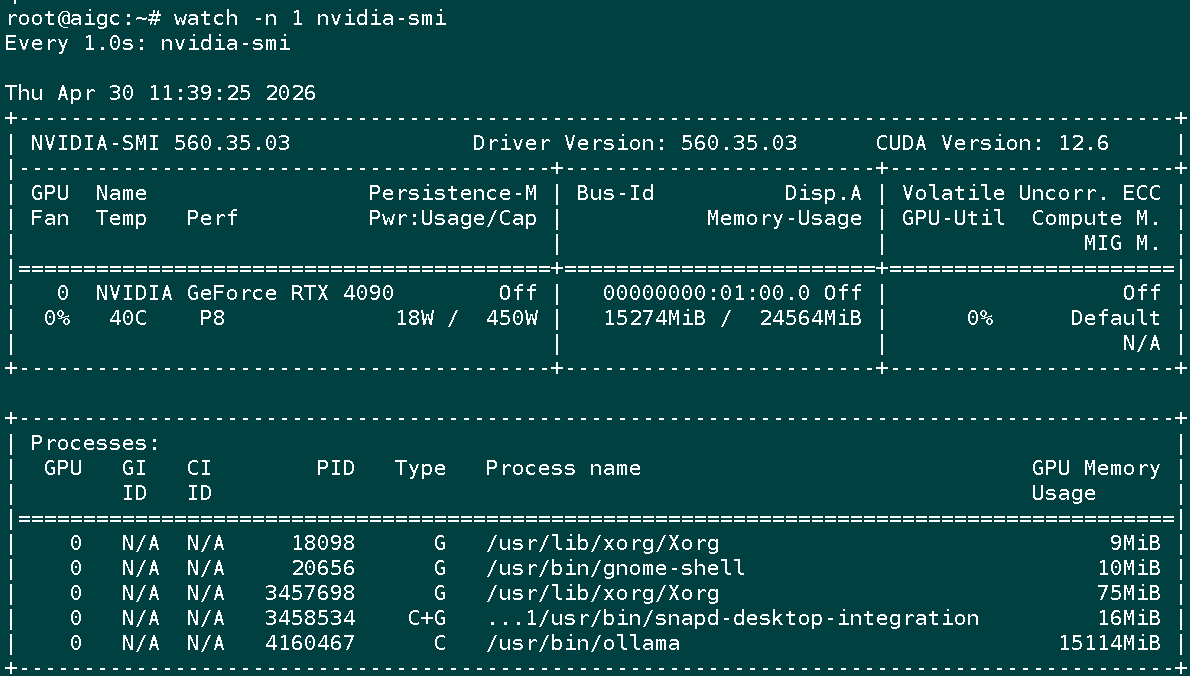
| Qwen2.5-Coder 14B | 15~17 GB | 0%~80% | 100% GPU |
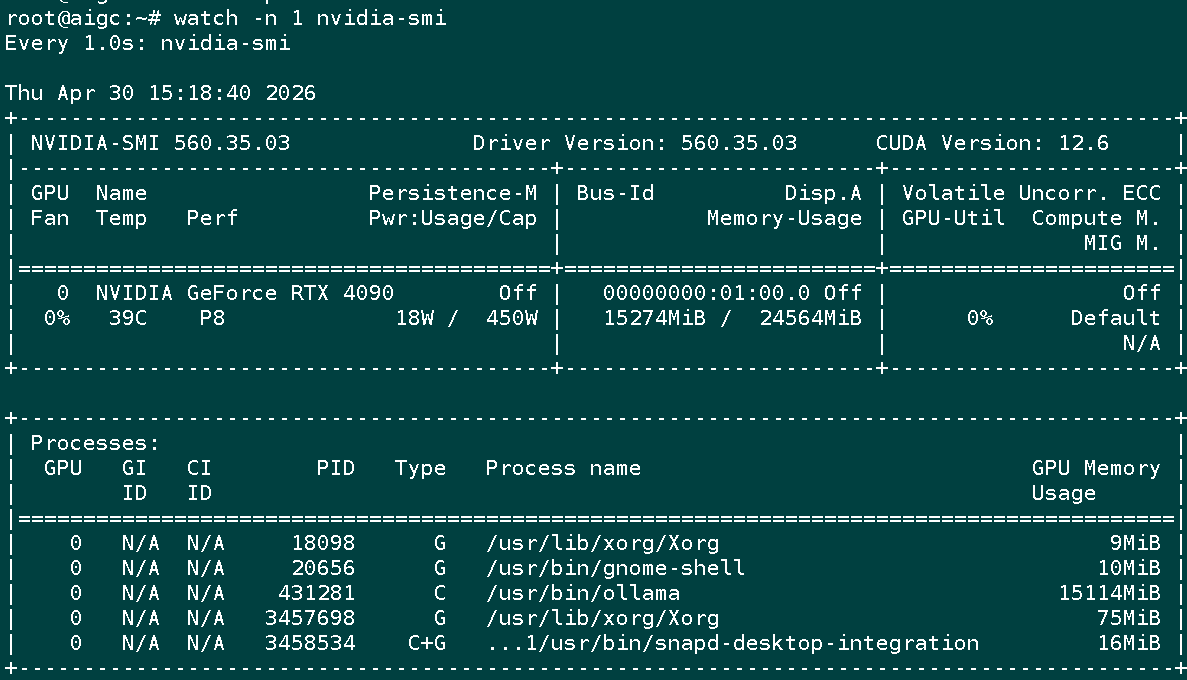
| DeepSeek-R1 14B | 15~17 GB | 0%~80% | 100% GPU |
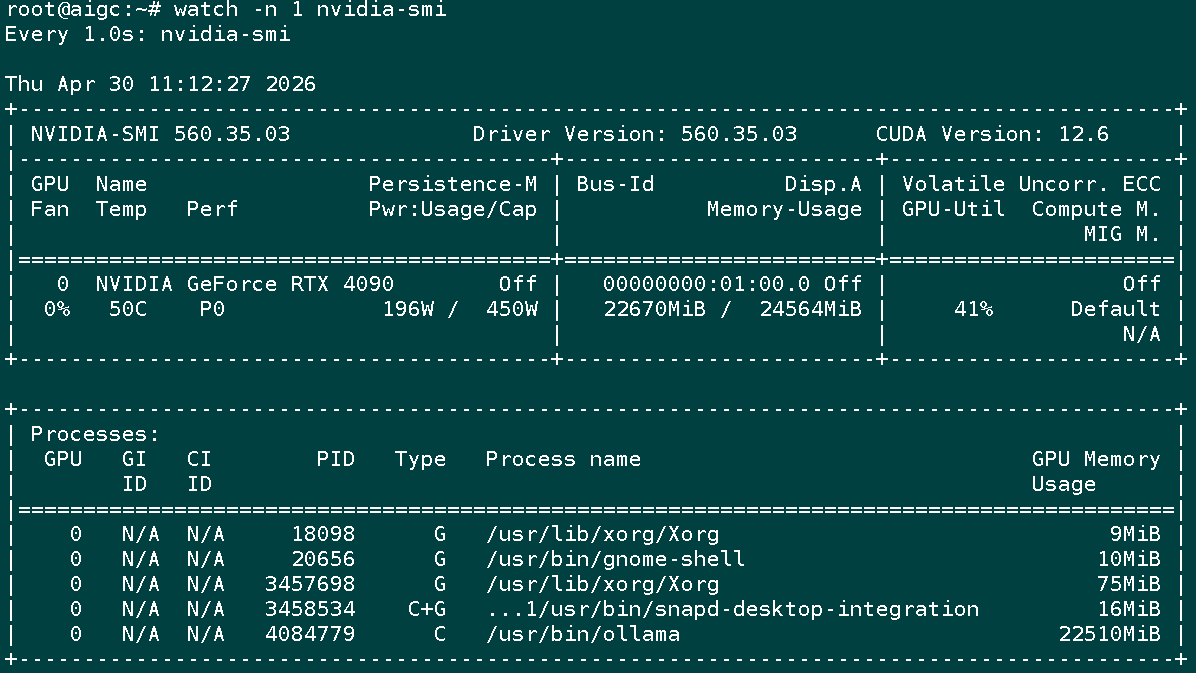
| Qwen3:27B | 22~24 GB | 30%~60% | 混合推理(约 90% GPU + 10% CPU) |
3、关键判断
| 指标 | 含义 |
|---|---|
| GPU-Util > 0 | 正在推理 |
| 显存占用 | 模型已加载 |
| PROCESSOR = 100% GPU | 纯 GPU 加速(正常) |
| PROCESSOR 含 CPU | 混合推理(异常,性能下降) |
1) qwen2.5-coder:14b 模型输出示例:
2)qwen3:27b 模型输出示例(混合推理):

3)deepseek-r1:14b 模型输出示例:
4、排查命令
nvidia-smi
journalctl -u ollama -f | grep -i cuda
id ollama六、安全扫描场景对比测试
使用同一扫描器(Zack-AI-Scanner)、同一目标(http://192.168.25.207/control/login.php)、同一载荷集进行对比测试。
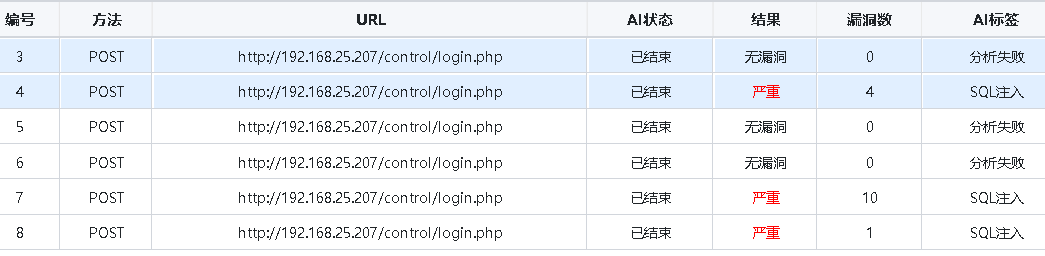
1、测试结果汇总
| 对比维度 | Qwen2.5-Coder 14B | DeepSeek-R1 14B | Qwen3:27B |
|---|---|---|---|
| 发现漏洞数 | 10 个 | 1 个 | 未测试(显存不足) |
| 扫描耗时 | 约 15 秒 | 约 76 秒 | 不适用 |
| 综合风险 | 严重 | 严重 | 严重 |
| 推理模式 | 100% GPU | 100% GPU | 混合推理 |
| 分析质量 | 详细(逐条分析载荷) | 粗略(仅分析1条) | 不适用 |
| 响应稳定性 | 稳定 | 稳定 | 不稳定(CPU offload) |
2、详细分析
1)Qwen2.5-Coder 14B(表现最佳)
- 发现 10 个 SQL 注入漏洞
- 对每个载荷都有具体分析,例如判断
' OR '1'='1导致 302 Found 并重定向到we_bug_env.php,证明存在 SQL 注入 - 能够识别不同注入位置(username、password、Cookie、submit 参数)
- 响应速度快,用户体验流畅
2)DeepSeek-R1 14B(表现一般)
- 仅发现 1 个 SQL 注入漏洞
- 分析粒度较粗,描述泛化(仅提到“响应包含 MySQL 错误”)
- 未能识别多个注入点
- 速度明显慢于 Qwen(76秒 vs 15秒)
3)Qwen3:27B(不推荐)
- 显存需求 25~30GB,超出 4090 单卡容量
- 必然发生 CPU offload,导致混合推理
- 性能抖动明显,响应延迟高
- 即使优化参数(OLLAMA_CONTEXT_LENGTH=8192、OLLAMA_MAX_LOADED_MODELS=1)仍无法避免 CPU 参与
- 结论:可以运行,但体验一般,不建议作为主力
七、常用管理命令
ollama list # 查看本地模型
ollama ps # 查看当前运行模型
ollama stop <模型名> # 停止模型
pkill ollama # 强制释放显存八、API 调用(本地服务)
curl http://127.0.0.1:11434/api/generate -d '{
"model": "qwen2.5-coder:14b",
"prompt": "分析以下代码的SQL注入风险:..."
}'安全/IT 场景提示词示例
- 漏洞分析:
分析以下HTTP请求/响应,判断是否存在SQL注入漏洞 - 日志分析:
分析以下nginx错误日志,找出可能的安全问题 - 脚本生成:
写一个bash脚本,批量扫描某网段的22端口是否开放 - 漏洞解读:
解释CVE-2024-XXXX的漏洞原理和修复方案
九、性能优化建议
export OLLAMA_NUM_PARALLEL=1 # 限制并发
export OLLAMA_KEEP_ALIVE=0 # 自动释放显存针对 27B 模型的额外尝试(仍无法解决 CPU 参与问题):
export OLLAMA_CONTEXT_LENGTH=8192
export OLLAMA_MAX_LOADED_MODELS=1十、最终结论
| 模型 | 推荐度 | 适用场景 | 原因 |
|---|---|---|---|
| Qwen2.5-Coder 14B | ⭐⭐⭐⭐⭐ 主力 | 日常安全扫描、漏洞检测、代码分析 | 检出率最高、速度最快、分析最准、纯 GPU 运行 |
| DeepSeek-R1 14B | ⭐⭐⭐ 备选 | 复杂攻击链分析、多步渗透测试规划 | 检出率低、速度慢,但推理能力强,适合深度分析 |
| Qwen3:27B | ⭐ 不推荐 | 仅测试验证 | 显存不足导致混合推理,性能不稳定 |