适用场景:
- 检测 SAS/SATA HDD/SSD 的健康状态(支持 RAID 控制器管理的磁盘)。
- 结合
fdisk确认磁盘容量、分区及物理/虚拟磁盘映射关系。
1. 安装工具
sudo apt update && sudo apt install smartmontools -y2. 使用 fdisk 确认磁盘信息
(1)列出所有磁盘及型号
sudo fdisk -l | grep "Disk /dev/"输出示例:

关键信息:
/dev/sda:物理硬盘(no-raid)。/dev/sdb和/dev/sdc:PERC RAID 虚拟磁盘(需通过megaraid,N访问物理盘)。/dev/sdd:物理 SSD(no-raid)
(2)查看磁盘分区详情
sudo fdisk -l /dev/sdX # 替换为具体设备(如 /dev/sda)3. 快速获取所有磁盘基本信息
for i in {0..7}; do
echo "==== megaraid,$i ===="
sudo smartctl -i -d megaraid,$i /dev/sdb | grep -E "Device Model|Serial|Power_On_Hours"
done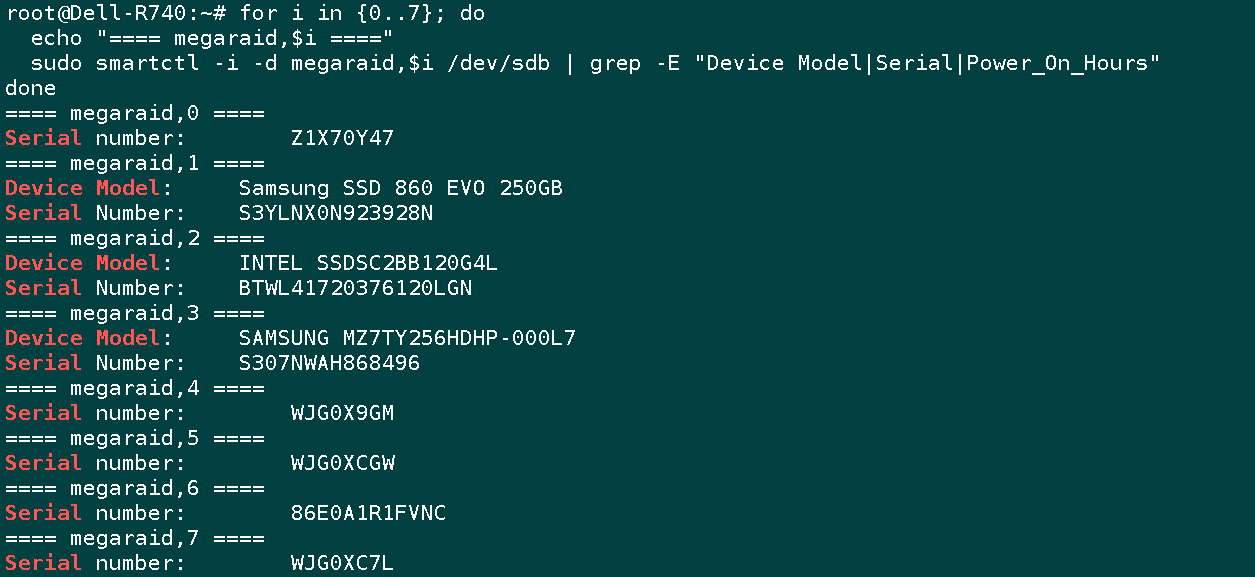
4. 核心健康指标检查(通电时间+错误计数)
for i in {0..7}; do
echo "==== 检测磁盘(0~7共8个盘位) megaraid,$i ===="
sudo smartctl -a -d megaraid,$i /dev/bus/0 | grep -E "SMART Health|Serial|Model|Power_On_Hours|Temperature|Error counter|Reallocated_Sector_Ct|Media_Error|Non-medium"
echo "------------------------"
done
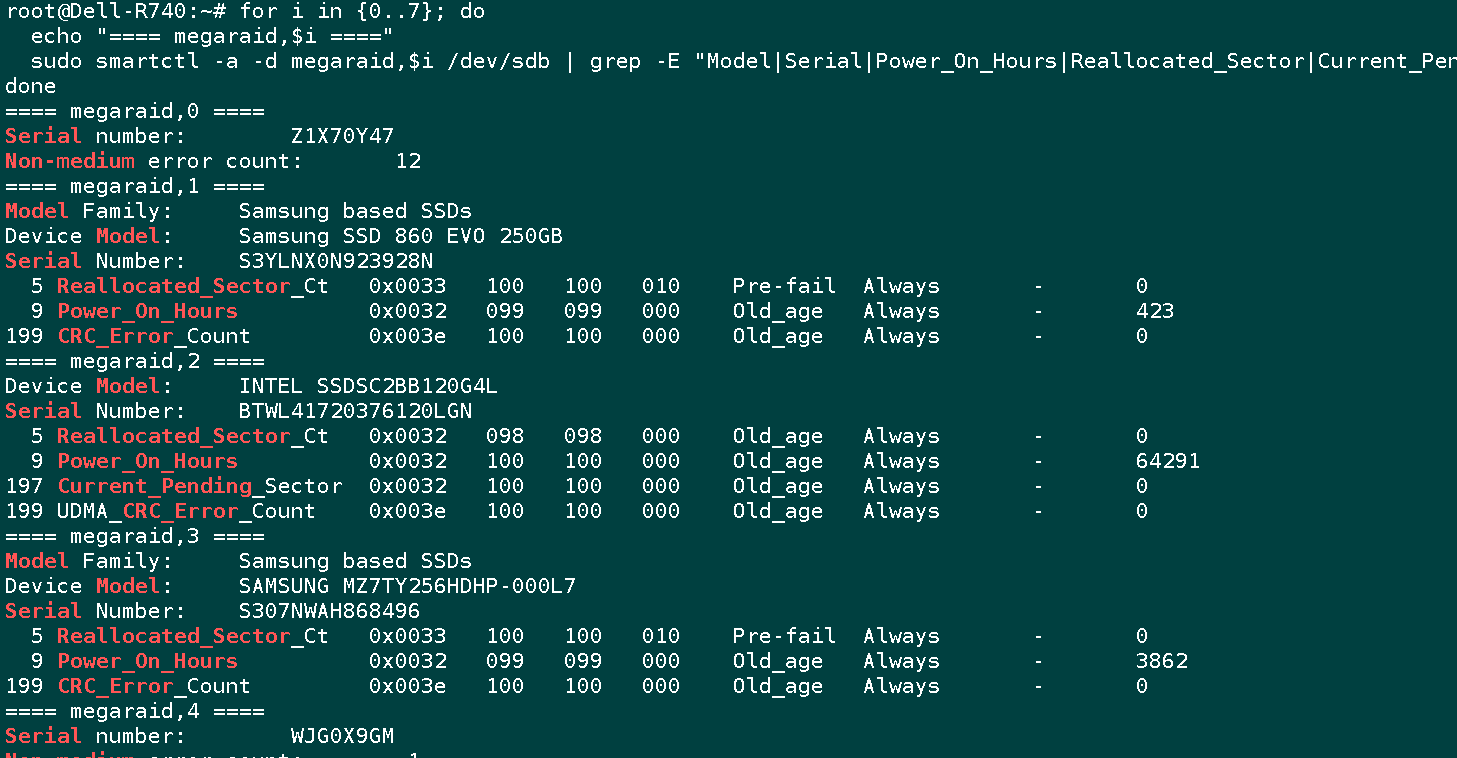
假如以上命令不支持,或者需要获取完整信息,用下面这个命令
smartctl -x -d megaraid,0 /dev/bus/0
…
smartctl -x -d megaraid,3 /dev/bus/0
关键指标:
Power_On_Hours:通电时间(>5万小时需警惕)。Reallocated_Sector_Ct:重分配扇区(>10需更换)。Current_Pending_Sector:待映射扇区(>0表示坏道)。Non-medium error count:非介质错误(>10可能为接口问题)。
5. 直接查看附件表格对应数据
| 序列号 | 通电时间 | 温度 | 读错误 | 写错误 | 校验错误 | 健康建议 |
|---|---|---|---|---|---|---|
| WJG0X9GM | 39175小时 | 39°C | 0次 | 0次 | 0次 | 正常 |
| WJG0XCGW | 38324小时 | 39°C | 0次 | 0次 | 0次 | 正常 |
| WJG0X6AQ | 39176小时 | 38°C | 0次 | 1次 | 36次 | 校验错误高,需更换 |
| WJG0XCTL | 38324小时 | 38°C | 1次 | 0次 | 0次 | 监控读错误是否增长 |
6. 重点磁盘处理建议
- 序列号
WJG0X6AQ- 校验错误36次:可能存在介质老化或接口问题,建议更换。
- 序列号
WJG0XCTL- 读错误1次:暂时观察,若持续增加需更换。
- 通电时间超5万小时的磁盘
- 如
megaraid,0(71746小时):备份数据并计划更换。
- 如
7. 一键生成健康报告
echo "硬盘健康报告 $(date)" > disk_health.txt
for i in {0..7}; do
echo "==== megaraid,$i ====" >> disk_health.txt
sudo smartctl -a -d megaraid,$i /dev/sdb | grep -E "Model|Serial|Power_On_Hours|Reallocated|Pending|CRC|Non-medium" >> disk_health.txt
done查看报告:
cat disk_health.txt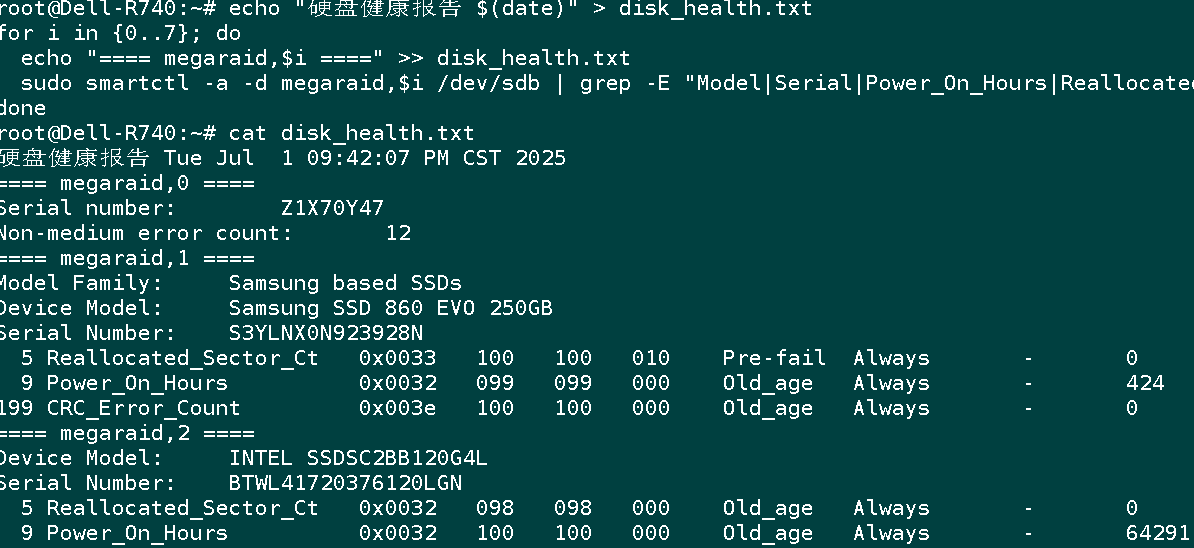
8.总结
- 基础命令:用
smartctl -i快速列表,用smartctl -a查细节。 - 核心指标:盯紧通电时间、重分配扇区、待映射扇区、错误计数。
- 附件对照:直接对比表格中的错误次数和温度。
- 高危磁盘:校验错误多或通电超限的盘优先更换。
只需这4步,5分钟完成全部磁盘健康检查!